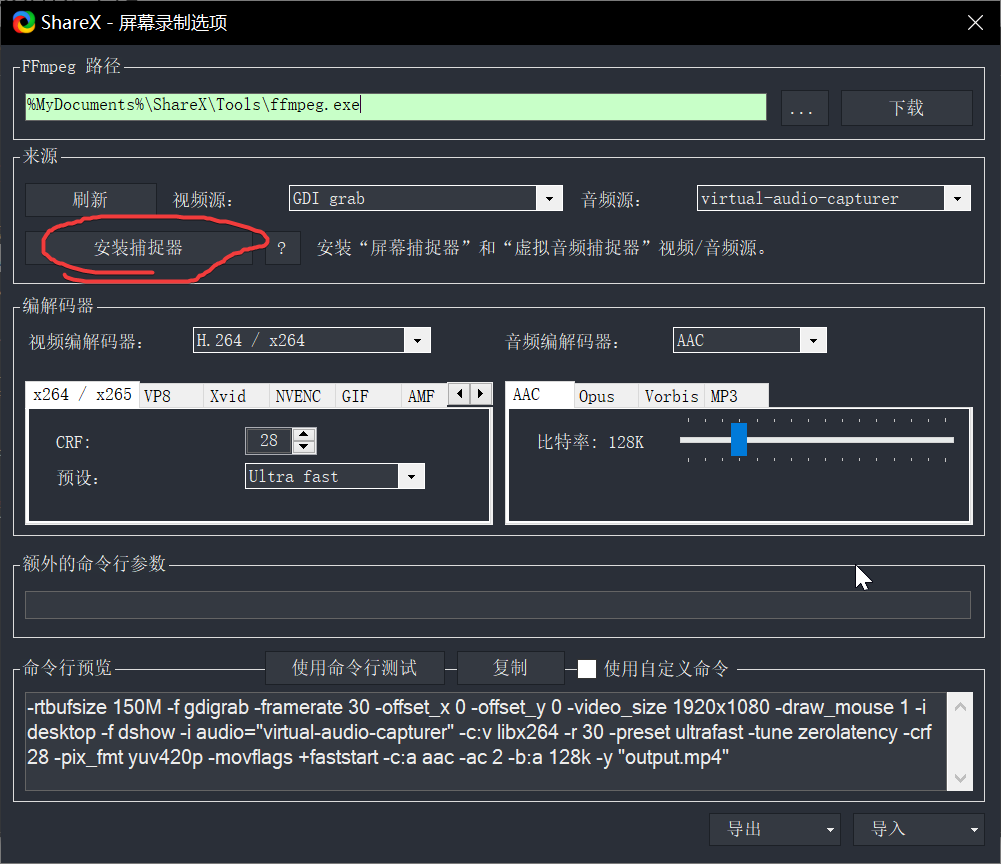
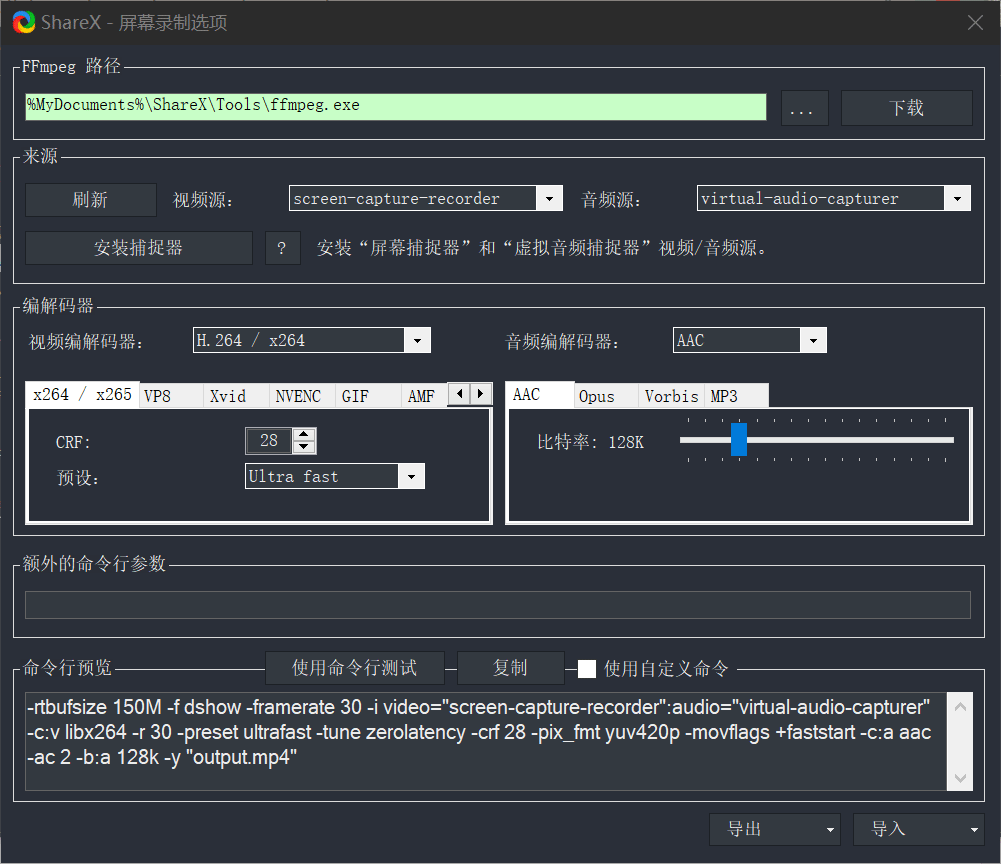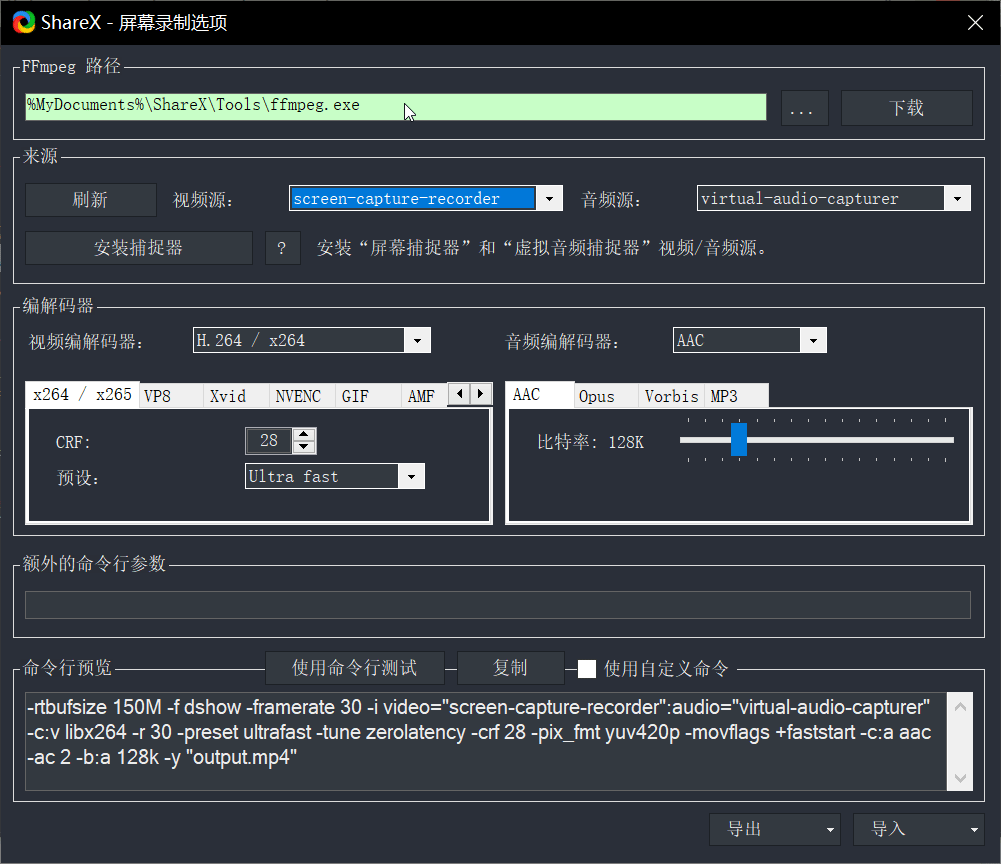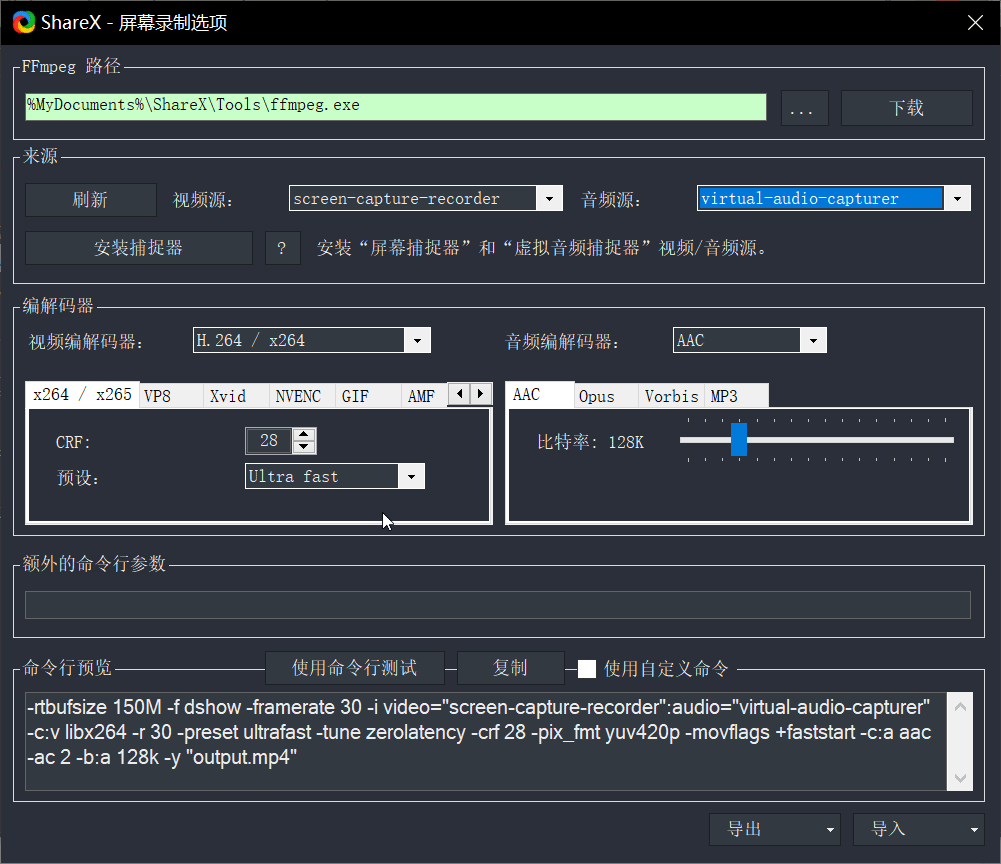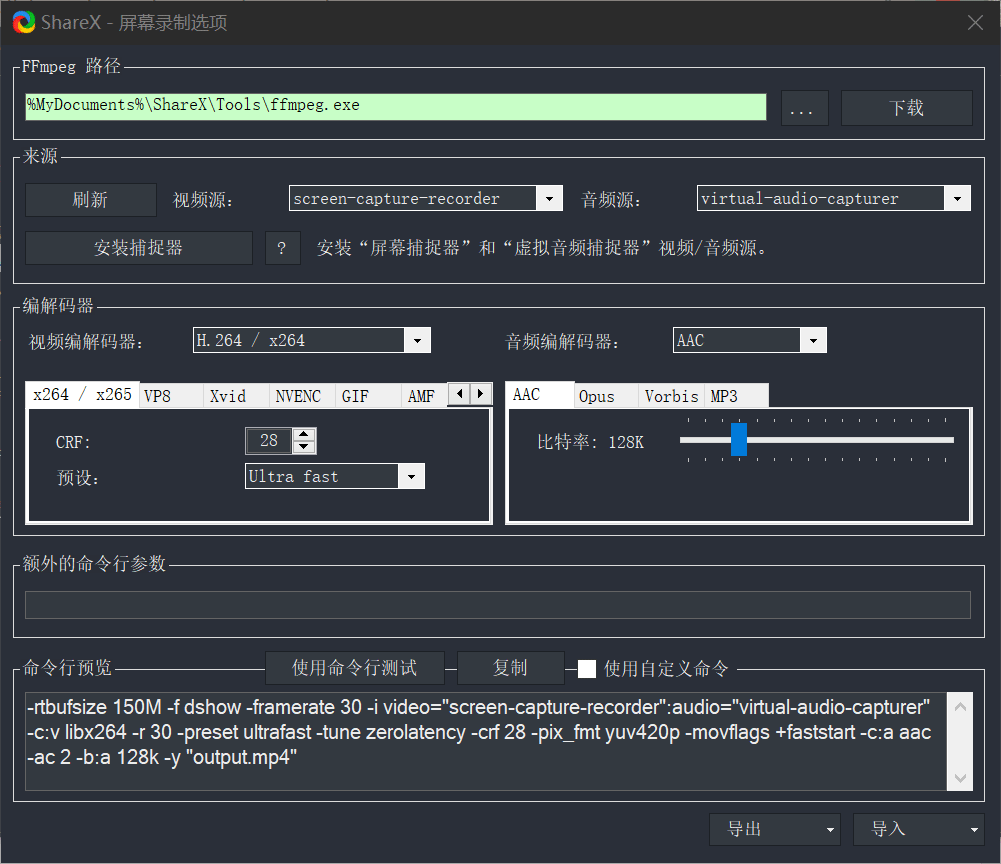
gRPC是google提供的一套基于HTTP/2和protobuf的RPC框架,支持多种语言,包括python。
实现一个异步的Request/Reply调用的服务器和客户端 首先需要安装gRPC库,截止发稿时最新版本为1.58.0。
1 pip install grpcio grpcio-tools
再编写一个helloworld的proto文件,gRPC根据proto文件来生成客户端和服务端的代码,下面是一个简单的helloworld.proto文件。官方文档 。
protos/helloworld.proto
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 syntax = "proto3" ; package helloworld;service Greeter { rpc SayHello (HelloRequest) returns (HelloReply) } message HelloRequest { string name = 1 ; } message HelloReply { string message = 1 ; }
本示例中定义了两个数据类型HelloRequest和HelloReply,分别对应发送请求和相应的数据结构。
proto文件编写完成后运行gRPC命令行工具生成相关的类。
1 python -m grpc_tools.protoc -I protos --python_out=. --pyi_out=. --grpc_python_out=. protos/helloworld.proto
生成命令完成后会在项目当前文件夹下生成helloworld_pb2_grpc.py和helloworld_pb2.py两个文件,分别包含了客户端和服务端需要用到的类。
下面编写服务器程序。
async_greeter_server.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import grpcimport helloworld_pb2import helloworld_pb2_grpcclass Greeter (helloworld_pb2_grpc.GreeterServicer): async def SayHello ( self, request: helloworld_pb2.HelloRequest, context: grpc.aio.ServicerContext, ) -> helloworld_pb2.HelloReply: return helloworld_pb2.HelloReply(message="Hello, %s!" % request.name) async def serve () -> None : server = grpc.aio.server() helloworld_pb2_grpc.add_GreeterServicer_to_server(Greeter(), server) listen_addr = "[::]:50051" server.add_insecure_port(listen_addr) logging.info("Starting server on %s" , listen_addr) await server.start() await server.wait_for_termination() if __name__ == "__main__" : logging.basicConfig(level=logging.INFO) asyncio.run(serve())
客户端程序, async_greeter_client.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import asyncioimport loggingimport grpcimport helloworld_pb2import helloworld_pb2_grpcasync def run () -> None : async with grpc.aio.insecure_channel("localhost:50051" ) as channel: stub = helloworld_pb2_grpc.GreeterStub(channel) response = await stub.SayHello(helloworld_pb2.HelloRequest(name="you" )) print ("Greeter client received: " + response.message) if __name__ == "__main__" : logging.basicConfig() asyncio.run(run())
运行python async_greeter_server.py启动服务器,再运行python async_greeter_client.py启动客户端,可以看到客户端收到了服务器返回的数据。
在服务器实现一个流请求 protos/helloworld.proto
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 syntax = "proto3"; package helloworld; service Greeter { rpc SayHello (HelloRequest) returns (HelloReply) {} rpc SayHelloStreamReply (HelloRequest) returns (stream HelloReply) {} } // The request message containing the user's name. message HelloRequest { string name = 1; } // The response message containing the greetings message HelloReply { string message = 1; }
在Greeter服务上增加一个方法SayHelloStreamReply,接受一个HelloRequest参数,返回一个HelloReply类型的流。
服务器程序中实现SayHelloStreamReply方法,每隔1秒向客户端返回一个HelloReply.
async_greeter_server.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import asyncioimport loggingimport grpcimport helloworld_pb2import helloworld_pb2_grpcclass Greeter (helloworld_pb2_grpc.GreeterServicer): async def SayHello ( self, request: helloworld_pb2.HelloRequest, context: grpc.aio.ServicerContext, ) -> helloworld_pb2.HelloReply: return helloworld_pb2.HelloReply(message="Hello, %s!" % request.name) async def SayHelloStreamReply ( self, request: helloworld_pb2.HelloRequest, context: grpc.aio.ServicerContext, ) -> helloworld_pb2.HelloReply: for i in range (10000 ): await asyncio.sleep(1 ) yield helloworld_pb2.HelloReply(message="Hello, %s! %d" % (request.name, i)) async def serve () -> None : server = grpc.aio.server() helloworld_pb2_grpc.add_GreeterServicer_to_server(Greeter(), server) listen_addr = "[::]:50051" server.add_insecure_port(listen_addr) logging.info("Starting server on %s" , listen_addr) await server.start() await server.wait_for_termination() if __name__ == "__main__" : logging.basicConfig(level=logging.INFO) asyncio.run(serve())
客户端程序 async_greeter_client.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import asyncioimport loggingimport grpcimport helloworld_pb2import helloworld_pb2_grpcasync def run () -> None : name = sys.argv[1 ] if len (sys.argv) > 1 else "world" async with grpc.aio.insecure_channel("localhost:50051" ) as channel: stub = helloworld_pb2_grpc.GreeterStub(channel) response = await stub.SayHello(helloworld_pb2.HelloRequest(name=name)) print ("Greeter client received: " + response.message) async with grpc.aio.insecure_channel("localhost:50051" ) as channel: stub = helloworld_pb2_grpc.GreeterStub(channel) request = helloworld_pb2.HelloRequest(name=name) response_stream = stub.SayHelloStreamReply(request) async for res in response_stream: print ("Greeter client received:" , res.message) if __name__ == "__main__" : logging.basicConfig() asyncio.run(run())
服务器从一个业务服务中获取流并返回给客户端 这样就实现向客户端输出流了。
但是有时候我们需要这个服务从其他服务的状态中获取信息再返回给客户端。怎么办呢。
增加一个CustomerCenter业务单元,如果有顾客进店client_enter则把客户登记上,
async_greeter_server.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 import asynciofrom collections import defaultdictfrom datetime import datetimeimport loggingimport grpcimport helloworld_pb2import helloworld_pb2_grpcclass CustomerCenter : def __init__ (self ): self.clients = {} self.client_queues = defaultdict(asyncio.Queue) async def start (self ): while True : await asyncio.sleep(1 ) for client_name in self.clients.keys(): await self.client_queues[client_name].put("hello " + client_name + ", it's " + datetime.now().strftime("%Y-%m-%d %H:%M:%S" )) def client_enter (self, client_name ): """ a client enter """ self.clients[client_name] = '' def client_leave (self, client_name ): """ a client leave the center """ print ('client %s is leaving.' % client_name) self.clients.pop(client_name) self.client_queues.pop(client_name) def get_queue (self, client_name ): return self.client_queues[client_name] class Greeter (helloworld_pb2_grpc.GreeterServicer): def __init__ (self, customer_center:CustomerCenter ): self.customer_center = customer_center async def SayHello ( self, request: helloworld_pb2.HelloRequest, context: grpc.aio.ServicerContext, ) -> helloworld_pb2.HelloReply: return helloworld_pb2.HelloReply(message="Hello, %s!" % request.name) async def SayHelloStreamReply ( self, request: helloworld_pb2.HelloRequest, context: grpc.aio.ServicerContext, ) -> helloworld_pb2.HelloReply: self.customer_center.client_enter(request.name) queue = self.customer_center.get_queue(request.name) while True : message = await queue.get() yield helloworld_pb2.HelloReply(message=message) async def serve () -> None : server = grpc.aio.server() customer_center = CustomerCenter() helloworld_pb2_grpc.add_GreeterServicer_to_server(Greeter(customer_center), server) listen_addr = "[::]:50051" server.add_insecure_port(listen_addr) logging.info("Starting server on %s" , listen_addr) asyncio.create_task(customer_center.start()) await server.start() await server.wait_for_termination() if __name__ == "__main__" : logging.basicConfig(level=logging.INFO) asyncio.run(serve())
处理客户端断开链接事件 到这里可以发现一个问题,如果客户端关闭了,下次再打开时,离开期间也会生成事件,服务器并
可以捕获asyncio.CancelledError异常来获取客户端断开事件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 async def SayHelloStreamReply ( self, request: helloworld_pb2.HelloRequest, context: grpc.aio.ServicerContext, self.customer_center.client_enter(request.name) queue = self.customer_center.get_queue(request.name) try : while True : message = await queue.get() yield helloworld_pb2.HelloReply(message=message) except asyncio.CancelledError: print (f'client {request.name} disconnected.' ) self.customer_center.client_leave(request.name)
1 2 3 4 5 6 $ python async_greeter_server.py INFO:root:Starting server on [::]:50051 client you disconnected. client you is leaving. client you disconnected. client you is leaving.
多态事件类型 有的时候我们希望一个订阅接口成为总线,客户端进行一次调用即可收到不同类型的消息,即多态机制。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 syntax = "proto3"; package helloworld; // The greeting service definition. service Greeter { // Sends a greeting rpc SayHello (HelloRequest) returns (HelloReply) {} rpc SayHelloStreamReply (HelloRequest) returns (stream HelloReply) {} rpc SayHelloBidiStream (stream HelloRequest) returns (stream HelloReply) {} rpc SayHelloStream2 (HelloRequest) returns (stream GreetingMessage) {} } // The request message containing the user's name. message HelloRequest { string name = 1; } // The response message containing the greetings message HelloReply { string message = 1; } message GreetingMessage { oneof shape_type { FirstGreetingMessage firstGreetingMessage = 1; TimerGreetingMessage timerGreetingMessage = 2; GoodbyeGreetingMessage goodbyeGreetingMessage = 3; } } message FirstGreetingMessage { } message TimerGreetingMessage { } message GoodbyeGreetingMessage { }
这里在proto中定义了一个主消息类型GreetingMessage,它的主要作用时作为下面三个具体消息类型FirstGreetingMessage, TimerGreetingMessage, GoodbyeGreetingMessage的容器,
服务器程序中依次返回 FirstGreetingMessage, TimerGreetingMessage, GoodbyeGreetingMessage消息。
async_greeter_server.py
1 2 3 4 5 6 7 8 9 10 11 12 async def SayHelloStream2 ( self, request: helloworld_pb2.HelloRequest, context: grpc.aio.ServicerContext, yield helloworld_pb2.GreetingMessage(firstGreetingMessage=helloworld_pb2.FirstGreetingMessage()) for i in range (5 ): await asyncio.sleep(1 ) yield helloworld_pb2.GreetingMessage(timerGreetingMessage=helloworld_pb2.TimerGreetingMessage()) yield helloworld_pb2.GreetingMessage(goodbyeGreetingMessage=helloworld_pb2.GoodbyeGreetingMessage())
客户端使用GreetingMessage对象的HasField函数检查具体是那种类型消息,并分别做相应处理。
async_greeter_client.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 async def run () -> None : name = sys.argv[1 ] if len (sys.argv) > 1 else "world" async with grpc.aio.insecure_channel("localhost:50051" ) as channel: stub = helloworld_pb2_grpc.GreeterStub(channel) response = await stub.SayHello(helloworld_pb2.HelloRequest(name=name)) print ("Greeter client received: " + response.message) async with grpc.aio.insecure_channel("localhost:50051" ) as channel: stub = helloworld_pb2_grpc.GreeterStub(channel) request = helloworld_pb2.HelloRequest(name=name) response_stream2 = stub.SayHelloStream2(request) async for res in response_stream2: res:helloworld_pb2.GreetingMessage = res if res.HasField('firstGreetingMessage' ): print ("firstGreetingMessage received:" , res.firstGreetingMessage) elif res.HasField('timerGreetingMessage' ): print ("timerGreetingMessage received:" , res.timerGreetingMessage) elif res.HasField('goodbyeGreetingMessage' ): print ("goodbyeGreetingMessage received:" , res.goodbyeGreetingMessage) else : print ('unknown message received.' )
1 2 3 4 5 6 7 8 9 $ python async_greeter_client.py hello Greeter client received: Hello, hello! firstGreetingMessage received: timerGreetingMessage received: timerGreetingMessage received: timerGreetingMessage received: timerGreetingMessage received: timerGreetingMessage received: goodbyeGreetingMessage received:
这样一个基于协程异步运行的消息订阅服务就基本上完成了。
参考资料